
Naive Bayes Classifier
- Roma Fatima
- Nov 30, 2021
- 3 min read

A Naive Bayes classifier is a probabilistic machine learning model that’s used for discriminate different objects based on certain features. The concept of the classifier is based on the Bayes theorem.

Using Bayes theorem, we can find the probability of A happening, given that B has occurred. Here, B is the evidence and A is the hypothesis. The assumption made here is that the predictors/features are independent. That is presence of one particular feature does not affect the other. Hence it is called naive.
The initial code for this classifier was taken from the Kaggle Competition Site and changes have been made on the same code.
We begin the program by importing classes numpy, pandas, math and operator. We read the IMDB movie review file and proceed to divide the data frame in ranges for training, developing and testing.

We calculate the probabilities of positive and negative reviews.

Output:

We count how many positive and negative reviews are present in each data set of training, testing and developing.




Printing Training data:

Printing Development data:

Printing Testing data:

We now proceed to clean the date by removing special characters and replacing all capital letters with small.

We now build a vocabulary list.

We omit rare words if the occurrence is less than five times.

Now the total vocabulary list is of 99 words.

We calculate the probabilities of the positive words and negative words.

We now conduct 5-Fold Cross Validation.


Output:

We now compare the effect of smoothing.

5-Fold Cross Validation after smoothing will be:


Output:

We compare the results and see if the effect of smoothing is better or not. We get an output that states the accuracy is better without smoothing.

We now derive Top 10 words that predicts positive and negative class

Positive words:

Output:

Negative words:

Output:

Finally, we calculate the final accuracy using hypermeters from above.


Output:

My Contribution:
With the help of referenced articles, I was able to increase the accuracy of the prediction to 50%.
1. I changed the ratio of Training, Testing and Developing data sets. In the following sections you will come across the many experiments I did on the program to find the best ratio suitable for this data frame. I was able to obtain the perfect range of data for training, developing and testing, which is Training: 0 - 25.30%, Developing 25.30 - 30% and Testing 30 - 100%.
2. Omitting rare words. I tested various word frequencies in the range of 1-10 and obtained the best for my program, which coincidentally is of 5. I removed all the words which don't occur more than 5 times in the data frame.
Challenges Faced:
As I was working solely on IMDB reviews data frame it was difficult improving the accuracy and the highest I could achieve was only 50%.
It was also a challenge to repeatedly run the program for about 50-70 times to find the best suitable ratio for Training, Testing and Developing data sets. It was solely on approximation and trial and error method.
Another challenge I faced was importing the files in Google collab and it staying in the RAM for more than 30 mins idle time. I had to import files repeatedly. This issue resolved on it's own.
Experiments:
From the Data Mining lectures, I learnt that Naive Bayes Classifier does not require a lot of training data for optimal classification. Hence in my first experiment, I ran the program with various data ranges for training, developing and testing data sets. The data is in percentage of the total data frame of IMDB movie reviews.

From this experiment I was able to obtain the perfect range of data for training, developing and testing, which is Training: 0 - 25.30%, Developing 25.30 - 30% and Testing 30 - 100%. This gives me the highest accuracy of 50% without smoothing.
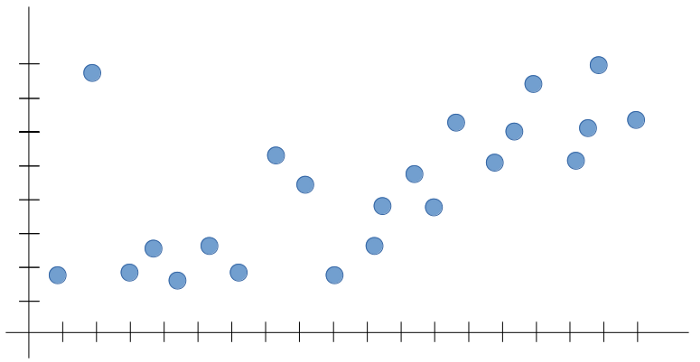
Another experiment I conducted was to see if changing the frequency of words can affect the accuracy. I got this idea from the referenced article which states that changing data ranges can change the probabilities of classification. I ran the program by changing frequencies from 0 to 10 times and obtained the following graph.

From this experiment, I came to a conclusion that using the minimum frequency of 5 times gives the highest accuracy of 50%.
References:
Explanation of Naive Bayes Classifier: https://towardsdatascience.com/naive-bayes-classifier-81d512f50a7c
Explanation of Naive Bayes Classifier from slides of CSE 5334 Data Mining course at UTA: https://uta.instructure.com/courses/88045/files/15438568?module_item_id=3762694
Image for Naive Bayes Classifier: https://towardsdatascience.com/introduction-to-na%C3%AFve-bayes-classifier-fa59e3e24aaf
Dataset of IMDB movie reviews: https://www.kaggle.com/marklvl/sentiment-labelled-sentences-data-set
Initial code of NBC on which the changes are made: https://www.kaggle.com/neeleshshashidhar/naive-bayes
Laplace smoothing: https://towardsdatascience.com/laplace-smoothing-in-na%C3%AFve-bayes-algorithm-9c237a8bdece
Ideas for my contribution/experiments: https://machinelearningmastery.com/better-naive-bayes/


Comments