
Term Project - Suicide Detection
- Roma Fatima
- Dec 7, 2021
- 5 min read

According to latest studies, in 2021, about 33% of Americans are suffering from depression. This means 1 in every 3 people are struggling mentally. When depression prevails for long, there is a high chance that people can develop suicidal tendencies. Forty percent of people with suicidal thoughts or behaviors do not seek medical care.
The main goal of this project is to analyze a person’s text post to detect if a they are feeling suicidal and if they are, we provide the National Suicide Prevention Lifeline number to them. This is a very useful app for people who are unaware of their mental health and/or have no one to help diagnose their depression. Providing the National Suicide Prevention Lifeline number at the right time can save their life.
Project Proposal:
Project Execution Video on YouTube:
Introduction:
This project analyzes text data and predicts suicidal tendencies based on the user's texts. The program analyzes the data, cleans it, creates a vocabulary of meaningful words, finds suitable hyperparameters, and based on that predicts if the user is suicidal or not, using Naive Baye's.
A Naive Bayes classifier is a probabilistic machine learning model that’s used for discriminate different objects based on certain features. The concept of the classifier is based on the Bayes theorem. The assumption made here is that the predictors/features are independent. That is presence of one particular feature does not affect the other. Hence it is called naive.
I have submitted my code on Kaggle as well as Google Colab:
I have also uploaded the files on Github:
We use a dataset that can be used to detect suicide and depression in a text. The dataset is a collection of posts from "SuicideWatch" and "depression" subreddits of the Reddit platform till Jan 2, 2021.

My app has a homepage of affirmation words encouraging people to write about their feelings, after swiping left it will open up a note page where people can write down about their feelings. This text is then classified when they click on the button ‘Save and Assess’.

Depending on their text input, they will get one of the 2 output pages,
first, where the output is displayed as ‘Person is not Suicidal’
and second, where the output is displayed as ‘Person is Suicidal. Seek help! Call: 800-273-8255’.


On the output pages we have an icon to go back to homepage and it is worthy to note that we have an emergency calling icon for people to directly call the National Suicide Prevention, on every page of the app.
My Contribution:
With the help of referenced articles, I was able to increase the accuracy of the prediction to 49.62%.
1. I changed the ratio of Training, Testing and Developing data sets. In the following sections you will come across the many experiments I did on the program to find the best ratio suitable for this data frame. I was able to obtain the perfect range of data for training, developing and testing, which is Training: 0 - 10%, Developing 10 - 50% and Testing 50 - 100%.
2. Omitting rare words. I tested various word frequencies in the range of 50-1150 and obtained the best for my program, which is of 850. I removed all the words which don't occur more than 850 times in the data frame.
3. I programmed a section where the user inputs their text and classification is performed on it. The output will detect if the person is suicidal or not.
We begin the program by importing classes numpy, pandas, math and operator. We read the Suicide_Detection.csv file.

We replace the column name from 'class' to 'situation' as class is a keyword and gives us errors in execution. We also drop the useless column of 'Unnamed: 0 '.

We then numerate the 'situation' column.

We drop the useless columns of 'situation' and 'non-suicide'.

We proceed to clean the data as much as possible.

From here the code snippets were obtained from referenced Kaggle website. The variables, datasets and their relation was adjusted according to the requirement.
We proceed to divide the data frame in ranges for training, developing and testing.

We now build a vocabulary list.

We omit rare words if the occurrence is less than 850 times as we are using large data.

We calculate the probabilities of the positive words and negative words.

We now conduct 5-Fold Cross Validation.


Output:

Smoothing plays an important role in improving accuracy.


Output:

We compare the results and see if the effect of smoothing is better or not. We get an output that states the accuracy is better without smoothing.

We now derive Top 10 words that predicts positive and negative class

Positive words:

Negative words:

Finally, we calculate the final accuracy using hypermeters from above.


Output:

We now test our classifier by taking the input from the user:
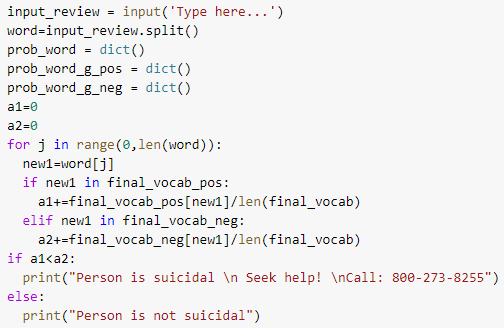
Test 1 : Using negative words.

Test 2 : Using positive words.

We come to a conclusion that this classifier works.
Experiments:
First experiment I conducted was to see if changing the frequency of words can affect the accuracy. I got this idea from the referenced article which states that changing data ranges can change the probabilities of classification.
The program initially had frequency of 5 words and accuracy of 37.34%.
I ran the program by changing frequencies from 50 to 1150 times and obtained the following graph.

From this experiment, I came to a conclusion that using the minimum frequency of 850 times gives the highest accuracy of 49.62%
Another experiment I conducted was changing the ratios of training, developing and testing datasets. The program initially had Training: 0 - 80%, Developing 80 - 90% and Testing 90 - 100%.

From the Data Mining lectures, I learnt that Naive Bayes Classifier does not require a lot of training data for optimal classification. Hence in this experiment, I ran the program with various data ranges for training, developing and testing data sets. The data is in percentage of the total data frame of 'texts'.
From this experiment I was able to obtain the perfect range of data for training, developing and testing, which is Training: 0 - 10%, Developing 10 - 50% and Testing 50 - 100%. This gives me the highest accuracy of 49.62% with smoothing.
Challenges Faced:
The biggest challenge was working on this large data which needed cleaning. It had a lot of gibberish, typing errors and many times had words combined without whitespaces. To overcome this challenge I had to clean the data before taking any action. For example you can see the data here in row 6:

Even after cleaning the data, the dataset wasn't perfect and still had some minor errors. We can see the same row 6 here after cleaning:

To bring out more accuracy, I then increased the frequency of words for the final vocabulary list, so that it can skip the common grammatical errors.
Another challenge I faced was 'Session Crashing'. To find the optimal ratio of training, developing and testing I had to run the program for nearly 40 times and then to check the word frequency's effect on accuracy I had to run the program for another 10 times. Since I am working on big data, this led to Google Colab crashing multiple times with the following error message:

To overcome this I had to keep saving my progress, retrieve data after it crashes, close background applications and also restart the system.
References:
Code references: https://www.kaggle.com/neeleshshashidhar/naive-bayes/notebook
Code references: https://www.kaggle.com/neeleshshashidhar/classifier
Code error corrections: https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.rename.html
Code error corrections: https://www.analyticsvidhya.com/blog/2021/01/a-guide-to-the-naive-bayes-algorithm/
Explanation of Naive Bayes Classifier from slides of CSE 5334 Data Mining course at UTA: https://uta.instructure.com/courses/88045/files/15438568?module_item_id=3762694
Understanding the coding of Naive Bayes: https://www.youtube.com/watch?v=PPeaRc-r1OI
Laplace smoothing: https://towardsdatascience.com/laplace-smoothing-in-na%C3%AFve-bayes-algorithm-9c237a8bdece
Ideas for my contribution/experiments: https://machinelearningmastery.com/better-naive-bayes/
Dataset obtained from: https://www.kaggle.com/nikhileswarkomati/suicide-watch
Code error corrections: https://stackoverflow.com/questions/39132563/check-if-user-input-contains-a-word-from-an-array-python-3
Code error corrections: https://www.askpython.com/python/list/find-string-in-list-python
Ideas for my contribution/experiments: https://machinelearningmastery.com/better-naive-bayes/
Introduction explanation: http://jaychaphekar.uta.cloud/uncategorized/jay-chaphekar/
Reddit information: https://en.wikipedia.org/wiki/Reddit
Depression study: https://www.bu.edu/articles/2021/depression-rates-tripled-when-pandemic-first-hit/
Applications for depression detection: https://bmcmedicine.biomedcentral.com/articles/10.1186/s12916-019-1461-z
Picture reference: https://mindful-minds.tumblr.com/post/171883785868/whatever-youre-going-through-just-know-that
Picture of blog: https://favim.com/image/3734613/


Comments